Welcome to WordPress. This is your first post. Edit or delete it, then start writing!
Author: yulianav
-
Effective Communication in Engineering Teams
Introduction
Communication isn’t just a soft skill. It’s the foundation of every high-performing engineering team. When done right, it enables clarity, alignment, and momentum. When neglected, it can slow down progress, create frustration, and even unravel otherwise great projects.
In engineering, where complex systems are built by cross-functional teams, communication is not optional, it’s strategic. Through my years of experience leading teams, I’ve seen communication make or break project outcomes.
Types of Communication in Engineering Teams
Asynchronous Communication
– Best for when people work across time zones or need focus time.
– Clear, concise, and context-rich messages are key.Example: In one project, we introduced a practice where every update in Jira required a short note outlining context, blockers, and potential impact. This dramatically reduced confusion and duplicated work.
Another example: Quite often, we agreed with the Engineers to have our daily updates in writing, either in a specific shared file or in the dedicated channel in Slack. It helped everyone to stay updated despite the time zone they worked in.
Synchronous Communication
– Ideal for real-time alignment and fast decision-making.
– Requires active listening and making sure all voices are heard.Example: In cases of sudden critical changes, production hotfixes, the best solution was to have a quick call to discuss further actions needed from each team member. This approach always reduces the time for troubleshooting.
Written vs. Verbal
– Written is better for traceability.
– Verbal is better for empathy and nuance.Example: As already mentioned above, having daily updates written can help to keep track of performance as well as keeping the team accountable.
Another example: While written updates are essential for tracking progress and maintaining accountability, verbal communication, especially during 1:1s, plays a key role in supporting morale, offering real-time encouragement, and fostering trust on a more personal level.

Non-verbal Cues in Remote Work
– Emojis, response speed, punctuation, and formatting matter. For example, “ok” can sound passive-aggressive if not framed properly. Remote communication needs emotional intelligence.
Common Pitfalls & How to Avoid Them
– Assuming shared understanding: I’ve seen teams diverge for an entire sprint because assumptions were not clarified. I started a habit of closing discussions with a written “alignment summary.”
–Information overload: I once worked with a developer who would paste huge chunks of logs directly into Slack. To make communication more effective, we introduced a simple rule — always start with a short summary of the issue before sharing detailed logs or links. That way, everyone could quickly understand the context without having to sift through pages of text.
– Silence as a false signal: In retros, I realized some team members remained quiet not because they agreed, but because they didn’t feel confident enough to speak. I began inviting everyone in 1:1s to surface these unspoken concerns.
– Misaligned personalities: Pairing introverts with very talkative teammates sometimes caused tension. I helped them set communication preferences early on, and it smoothed collaboration significantly.What Worked in My Experience
– Document decisions, not just status: We maintained a live “decision log” in Confluence during a complex EdTech project. This created a source of truth everyone trusted.
– Create psychological safety: I regularly reminded junior devs that questions are welcome. One new hire later told me they felt safe asking a question they were otherwise afraid to raise, which helped us catch a data sync issue early.
– Proactive communication culture: We used Slack updates with a format: ‘Yesterday / Today / Blockers’. One engineer started using this format daily, and it helped the entire team stay informed.
– Standups with purpose: We moved away from “status updates” and introduced a habit of asking, ‘Do you need help with anything today?’ It turned our standups into real-time unblocking sessions.
– 1:1s for alignment and mentorship: These allowed for private feedback, mentorship, and course correction. In one case, a developer was struggling to speak up in sprint reviews, so we practiced together in 1:1s, and within a month, they were confidently leading demos.
– Tone in written communication: I once softened a tense code review culture by introducing a rule: ‘Always say what you liked before you critique.’ It made PR discussions much more productive and human.Communication in Crisis Moments
During one live classroom pilot, our EdTech platform experienced an API outage just as students and stakeholders joined the session. I immediately opened a Zoom with the team and another one with stakeholders.
While the backend team investigated, I calmly explained to stakeholders what was happening, provided a realistic ETA, and assured them that our team was on it. Meanwhile, I relayed real-time updates from engineers.
The issue was resolved within 15 minutes, but what stayed with me was how much the trust and transparency in that moment mattered more than the outage itself. Crisis is when leadership shows, and communication is its most vital tool.
Tailoring Communication to Different Team Members
Not everyone communicates the same way — and that’s okay. Part of my role as a manager was to adapt.
– For junior developers, I broke down larger decisions into digestible chunks and used Loom videos to walk them through architecture.
– With senior engineers, I favored collaborative architecture sessions and open-ended discussions where they could take initiative.
– For remote teammates in other time zones, I recorded meetings and provided written action items to ensure they were included asynchronously.
– I also asked everyone during onboarding how they preferred to receive feedback — some liked quick messages, others preferred scheduled 1:1s. That small question improved our team culture more than expected.Tools & Techniques I Recommend
– Slack: Use threads, emojis, and async updates — don’t let everything disappear in the firehose of channels.
– Confluence or Notion: Document decisions, sprint goals, and retros.
– Loom: For code walkthroughs and visual explanations when async text isn’t enough.
– Rotating meeting facilitators: Makes everyone feel ownership and builds empathy.
– Communication templates: Having formats for PRs, daily updates, and incident reporting saves time and improves clarity.Leadership Tip: Communication Starts With You
As a manager, how you show up — in words, tone, and consistency — shapes the team’s culture.
If you write clearly, they will too. If you stay calm during tension, others follow. If you’re vulnerable enough to admit when you miscommunicated, they’ll trust you more, not less.
Leadership is often quiet, and it sounds more like clarity, kindness, and the courage to listen deeply.
Conclusion
Communication isn’t a task. It’s your infrastructure. It connects the people to the purpose, the vision to the execution.
Whether you’re shipping features, managing conflict, or helping someone grow, every moment is a communication moment.
So speak with intention, listen with empathy, and lead with your words. Your team deserves it — and so do you.
-
The Power of Empathy in Tech Leadership: True Story
Introduction
In the race to deliver faster code, meet aggressive deadlines, and scale products globally, technology teams risk overlooking the human element that underpins sustainable success. Empathy, the ability to understand and share another person’s feelings, may feel at odds with data-driven cultures, yet it is precisely this human skill that elevates technical leadership from good to exceptional. By integrating empathy into every layer of decision-making, leaders can foster trust, ignite creativity, and build resilient organizations that thrive through change.
Why Empathy Matters in Tech
Bridging Communication Gaps
Technical experts and business stakeholders often speak different languages. A leader who listens empathetically can translate complex engineering constraints into business-friendly narratives, ensuring alignment on priorities and fostering mutual respect.
Fostering Psychological Safety
When team members feel heard and valued, they are more likely to voice concerns, share innovative ideas, and report issues early, critical behaviors for avoiding costly mistakes and driving continuous improvement.
Encouraging Diversity of Thought
Empathetic environments welcome diverse perspectives. By seeking to understand each individual’s background and motivations, leaders can assemble teams that innovate faster, solve problems more creatively, and adapt to shifting markets.
The Empathetic Leader’s Toolkit

Active Listening
I’ve always said that active listening is my strongest competence, and people are often unexpectedly surprised when I mention it. Yet for me, it isn’t just a feel-good skill; it’s a leadership superpower that keeps teams aligned and projects on track. True active listening goes beyond passively hearing words: it means fully engaging with the speaker’s intent, concerns, and emotions.
When a teammate shares a roadblock or a new idea, I make it a point to paraphrase what I’ve heard—“So what I’m understanding is…”—and then confirm back, “Is that right?” This simple two-step ritual does two critical things:
- Saves Time
Clearing up misunderstandings in real time means we don’t cycle through revisions later on. - Reduces Misalignment
In fast-paced development, even small misinterpretations can blow weeks of work off course. By checking in immediately, we catch assumptions before they solidify.
Over time, this habit has created a ripple effect: colleagues feel heard and valued, communication tightens, and we spot issues earlier. As a leader and manager, you can’t afford to merely listen—you must ensure you really understand. Active listening, done well, turns every conversation into an opportunity for clarity and collaboration.
Emotional Intelligence (EQ)
For me, emotional intelligence isn’t just about knowing myself—it’s also about deeply tuning into my team’s dynamics. Over the years, I’ve learned to recognize my own triggers and manage them effectively, especially during critical moments. Knowing when and how my emotional responses could affect my decisions has helped me remain balanced under pressure and make clearer, calmer choices.
But leadership EQ extends beyond the self. It’s essential to continuously observe team interactions and quickly notice when someone might be disengaged, overwhelmed, or silently struggling. I’ve made it a habit to proactively step in and address these situations before they escalate into bigger issues. Whether it’s a quiet team member who suddenly withdraws from discussions or a usually enthusiastic developer who seems unusually stressed, recognizing subtle changes allows me to intervene early, providing support or adjusting workloads as necessary.
Being proactive about my team’s morale is one of my core values as a leader. I’ve learned from experience that high-performing teams aren’t just technically skilled—they’re also emotionally resilient, cohesive, and supported. By actively managing both my own emotional responses and staying attuned to the emotional well-being of my team, I’ve created environments where everyone feels seen, understood, and empowered to perform at their best.
Compassionate Feedback
Giving feedback is an essential part of leadership, and for me, it’s always rooted in compassion. Constructive criticism is valuable, but it must be delivered in a way that doesn’t diminish someone’s self-esteem or sense of worth. As a leader, I keep in mind that we’re all evolving daily, myself included. Recognizing this shared growth helps frame feedback as something supportive, not punitive.
One of my core practices is highlighting the most important strengths and contributions my teammates bring to the table first. When I celebrate what people do well, it establishes trust and confidence, paving a smoother path when there’s room for improvement. My team knows me for being openly expressive with positive feedback, it’s immediate, genuine, and consistent. I ensure no one feels praise-deprived, because sincere recognition reinforces their value and contributions.
Because my team is accustomed to receiving appreciation, when I do need to deliver feedback about areas needing growth, it never feels harsh or personal. They already understand their worth; what I’m communicating is simply an adjustment, a slight improvement toward our common goals. By creating this foundation of positive reinforcement, compassionate feedback becomes an empowering tool rather than something intimidating, strengthening both individual confidence and overall team performance.
Building an Empathy-Driven Culture
Recruitment: Hiring for Heart and Head
Whenever I’m involved in a hiring process, I pay close attention not only to technical abilities but also to the overall vibe and emotional alignment a candidate brings to the team. Technical brilliance matters, of course, but it’s equally important to ensure that new team members harmonize with the existing team dynamic.
From experience, I’ve learned that even exceptionally skilled candidates might struggle if their personal style or emotional approach doesn’t mesh well with our team’s established culture. A simple mismatch in communication style or values can create friction, disrupt harmony, or lead to larger team challenges down the line.
That’s why I prioritize emotional fit and team synergy as critical factors when evaluating potential hires. Technical skills can often be learned or refined on the job, but emotional intelligence, positive attitude, and cultural compatibility are more deeply rooted qualities.
By consciously hiring for heart as much as for the head, I ensure that new teammates don’t just enhance our skill set, they strengthen our entire team’s emotional cohesion, collaboration, and empathy-driven culture.
Onboarding: Setting the Tone Early
From day one, it’s essential to engage newcomers actively and offer them emotional support as they find their footing. I’ve always believed that effective onboarding isn’t just about showing new team members how things work, it’s about creating an immediate sense of belonging, comfort, and clarity.
Providing frequent, thoughtful feedback early on helps newcomers understand their progress and reassures them they’re moving in the right direction. Establishing this comfort and trust from the very start lays the foundation for strong, long-term collaboration.
I remember several instances where people specifically joined the company because they wanted to be part of my team and experience my leadership. This recognition was both humbling and motivating—it pushed me to ensure their onboarding experience was welcoming, supportive, and inspiring. Knowing that they chose to join specifically because of my leadership, set high expectations, and challenged me to continuously uphold my standards.
By setting a positive, empathetic tone early in the onboarding process, I’ve seen firsthand how quickly new team members become productive, confident, and deeply committed—ultimately strengthening the team’s overall cohesion and effectiveness.
Continuous Learning: Embedding Empathy Practice
I believe a good leader sets the tone, the team creates the vibe, and together, they thrive and grow. To maintain a healthy standard of collaboration, compassion, and empathy, it’s essential to embed these practices consistently into our daily routines, not just during special training sessions or one-time workshops.
In my teams, I always make space for non-technical activities that strengthen our trust and emotional bonds. Activities like casual check-ins, team-building events, or simply grabbing lunch together regularly help foster genuine relationships that transcend purely professional interactions. When team members understand each other on a personal level, they naturally become more empathetic, patient, and supportive collaborators.
This continuous practice of empathy doesn’t happen accidentally; it must be intentionally nurtured. Over time, I’ve observed that teams who regularly invest in strengthening their emotional connections perform better, communicate openly, and handle challenges more effectively.
By actively embedding empathy and compassion into our team’s everyday interactions, I’ve created environments where growth and learning are ongoing, not just in skills and technology, but in emotional intelligence and human connection as well.
Overcoming Challenges
Balancing Empathy with Accountability
My team always knows two things about me: first, that I’m quick to recognize their achievements and always ready to support them in difficult moments; and second, that I hold everyone, including myself, accountable to deliver on our promises. Empathy and accountability aren’t opposing forces. In fact, they complement each other powerfully.
There’s sometimes a misconception that empathetic leaders are overly soft or hesitant to push people to meet commitments. But that’s not the case. Being empathetic doesn’t mean you become easily swayed or avoid putting pressure where it’s needed. Rather, empathy shapes how you maintain accountability.
Because I invest continuously in building trust and mutual respect, when it’s time to ask difficult questions—“Where are we on this? What happened to the agreed timeline?”—my team never feels attacked or undervalued. Instead, they recognize these moments as a necessary part of achieving our shared goals. Accountability conversations become less about pointing fingers and more about finding solutions together.
Ultimately, empathy allows me to hold people accountable without sacrificing the supportive atmosphere we’ve cultivated. My team knows that my expectations come from a place of genuine care and commitment to our collective success. This balance enables everyone to feel valued, respected, and motivated to deliver their best work.
Preventing Empathy Fatigue
Even the strongest and most empathetic leaders can become emotionally exhausted. We’re all human, after all, and everyone has tough days or moments when empathy feels harder than usual. In my experience, recognizing and managing this “empathy fatigue” is crucial for sustainable leadership.
One strategy that has helped me immensely is cultivating a supportive network within my team. Having teammates who can temporarily step into the emotional labor role when I’m feeling drained has been invaluable. It not only helps maintain team morale but also empowers others to grow into empathetic leaders themselves.
Outside my immediate team, I’ve found it equally important to have peers or mentors with whom I can share the everyday challenges and struggles of leadership. These relationships allow me to express vulnerability, recharge emotionally, and gain perspective. Being able to openly discuss experiences and receive support from trusted colleagues ensures I return to my team refreshed and ready to lead effectively again.
Acknowledging empathy fatigue isn’t a weakness, it’s self-awareness in action. By proactively managing emotional burnout and leaning on trusted support networks, I can sustain my ability to lead with empathy, compassion, and clarity over the long term.
Conclusion
Empathy is not a soft add-on. It is a strategic advantage in an industry defined by rapid change. By investing in empathetic leadership, tech organizations unlock deeper collaboration, drive innovation, and cultivate loyal teams.
- Saves Time
-
Managing Multiple Applications in an EdTech Project
Introduction
When people think of product development, they often imagine a single app. But in one of my most complex and rewarding projects, we weren’t building just one — we were building an entire ecosystem of applications designed to work together as a single, seamless EdTech platform.
This platform was created to bring interactive education to the classroom, complete with 3D visualizations, real-time chat, homework assessments, and attendance tracking. It wasn’t just about developing an app, it was about orchestrating the experience across them. The challenge wasn’t only technical, it was deeply architectural and organizational.
The Multi-App Ecosystem
The platform consisted of three interconnected applications, each with its own clearly defined function:
Class Presentation App: Designed for real-time teaching, this app includes 3D subject visualizations (biology, history, and more) and live chat features.
Homework App: Students could complete and submit assignments, and teachers could review and assess them.
Attendance App: Used to track classroom attendance, synced with live sessions and student profiles.Each app served a different purpose but had to feel like one unified product — visually, technically, and experientially.
Architectural Strategy & Integration
We used a microservices architecture to ensure scalability and fault isolation. Each app was a separate microservice, maintained independently, and connected via APIs. The backend was built using Node.js with Express.js, providing clean routing and business logic.
To maintain platform consistency, we used Flutter for all frontends, ensuring feature parity and a shared design system across iOS and Android with a single codebase.
We implemented a centralized authentication system via AWS Cognito, which allowed users to log in once and maintain their session seamlessly across all three apps.
For data access and integration:
– GraphQL enabled efficient querying and reduced payload sizes.
– AWS SQS handled asynchronous communication between microservices.
– WebSockets powered live data sync and real-time chat in the classroom presentation app.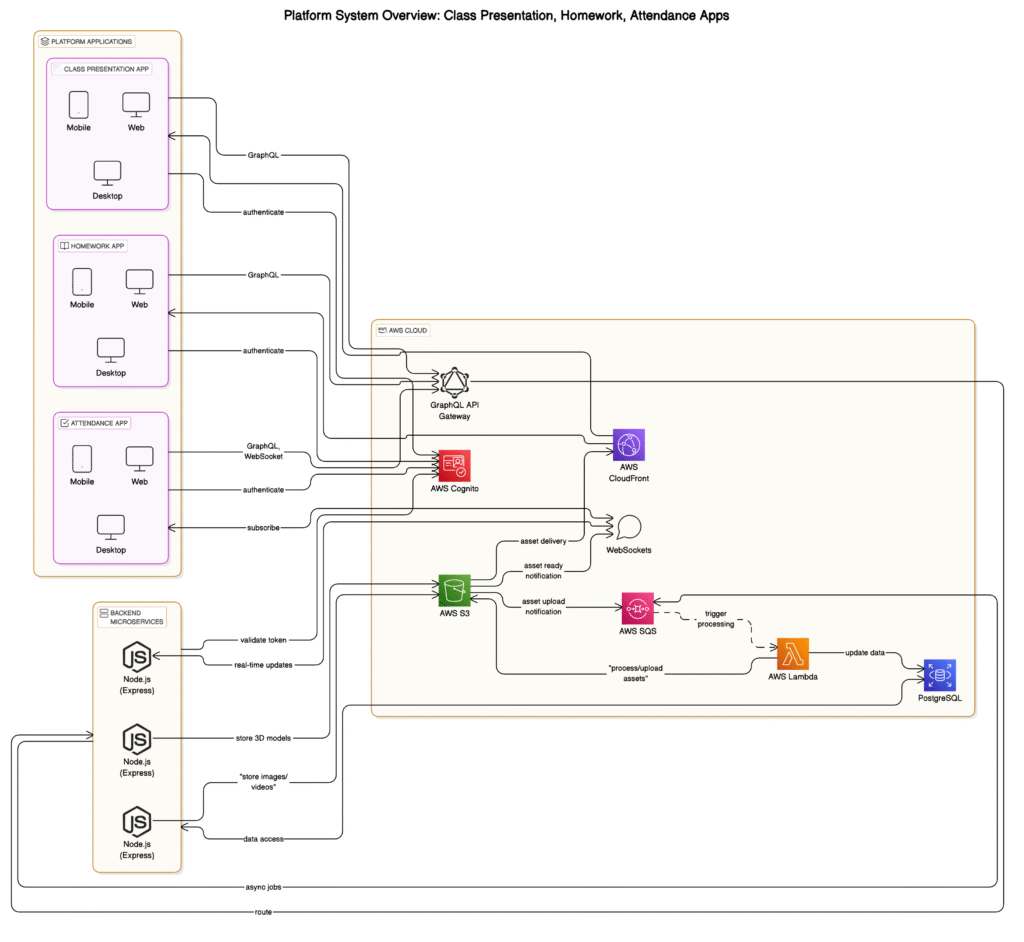
Scalability & Performance
To support scalability and performance, especially for 3D visualization, we leaned heavily on AWS:
– AWS RDS (PostgreSQL) for structured data.
– S3 for storing static assets like 3D models.
– CloudFront for fast content delivery.
– Lambda for handling lightweight backend tasks (e.g., automated reporting).For rendering 3D content inside mobile apps, we used WebGL and Three.js within Flutter. This created beautiful, interactive visuals, but came with performance challenges on older devices.
We implemented:
– Level of Detail (LOD) techniques to simplify distant 3D objects.
– Texture optimization for faster load times.
– GPU acceleration where available.
– And even custom Flutter shaders to offload rendering from the CPU.Team Coordination & Workflow
We worked with multiple teams: mobile developers, backend engineers, UI designers, and 3D artists. Coordination was key.
We used:
– Agile methodology with weekly sprints and daily standups.
– Jira for planning and tracking tasks.
– Git for clean code collaboration.
– And Confluence for documentation.Prioritization played a big role: Given its central importance to live teaching, we tackled the presentation app first. Homework and attendance followed in separate release cycles.
UX Consistency Across Apps
Using Flutter helped with consistency, but we still had to maintain a cohesive design and UX across all apps. We developed:
– A shared design system and reusable UI components.
– Custom widgets to ensure the same behavior and feel across all platforms.We encountered some platform-specific quirks — especially in handling notifications or permissions — but handled these with native code bridges where needed.
My Role as Engineering Manager
As the Engineering Manager, I wasn’t just overseeing timelines or tracking progress — I was actively shaping the technical vision, development process, and team culture behind the platform.
Technical Direction & Architecture
– Led key architectural decisions including microservices, Flutter, GraphQL/WebSockets.
– Worked closely with frontend/backend developers on scalable, maintainable solutions.Team Leadership, Collaboration & Mentorship
– Facilitated cross-functional standups, sprint planning, and collaborative workflows.
– Conducted code reviews, paired with engineers, and fostered technical ownership.
– Mentored junior developers — one even led a refactoring initiative after learning architectural patterns with me.
– Cultivated a team culture where questions, ideas, and ownership were encouragedProduct & Stakeholder Communication
– Acted as the tech-business bridge, aligning goals and defining realistic MVPs.
– Example: When stakeholders requested a gamified biology module, I negotiated scope, used existing assets creatively, and delivered a high-impact feature on time, without burning out the team.Crisis Handling & Adaptability
– Tackled mobile rendering issues, live sync bugs, and infrastructure bottlenecks head-on.
– Stayed hands-on and calm in pressure moments, prioritizing stability, delivery, and team morale.Lessons Learned
– Unifying multiple apps takes more than shared branding. It’s about strategic technical architecture and precise coordination.
– Early planning around authentication, data flows, and team responsibilities avoids huge rework later.
– Async communication patterns (like message brokers) are critical for modularity and scale.
– Real user feedback and MVP cycles help align stakeholders, especially in an educational context where needs evolve quickly.Conclusion
Leading this EdTech project taught me how to think across boundaries, between teams, tech stacks, and user experiences. Managing multiple apps is like conducting an orchestra: each piece must perform independently, but all must be in harmony.
Looking back, this project wasn’t just about building a product, it was about building a platform that empowered educators and students with cutting-edge tools for interactive learning. And that’s something I’ll always be proud of.
-
From Engineer to Leader: My Journey
Introduction
Starting Young
My journey started at the age of 15, when I was accepted into the Computer Academy, an institution that typically only admitted students aged 16 and up. They made an exception for me, and it was there that my passion for technology truly began to take shape. Initially, I had aspirations to be a Web Designer, drawn to the creative side of the tech world. However, after my first semester, I changed my major to Software Development. My programming teacher, with her inspiring approach to teaching, had a profound influence on me. The way she presented information and challenges opened my eyes to the potential of software development as a means to contribute more significantly to the tech world. I realized I could do much more than design static web pages—I could build dynamic, interactive, and functional systems.

Academic Success
Throughout my time at the academy, I was one of the top students in my class. I found myself constantly helping my classmates with difficult concepts and sharing my knowledge. Even students from other groups came to me for guidance, and I became well-respected among my peers. The principal of the academy even expressed a strong belief in my potential as a future specialist, which further fueled my motivation to excel.
Technological Focus
At the time, JavaScript technologies were seen as little more than fancy add-ons to HTML, so my primary focus was on C++ and C#. These languages formed the foundation of my programming knowledge, and I built on that as I grew in my career.
Freelancing and Digital Transformation
After graduating, I decided to dive into the real world by becoming a freelance web developer. I worked with various businesses, helping them embrace the digital world and transform their operations online. My role was crucial in guiding these companies through the digital transformation process, whether it was by creating their first website or developing more complex web applications that streamlined their business processes. This experience gave me invaluable exposure to the diverse needs of businesses and helped me understand how technology can drive growth and innovation.
The Shift
The Realization of Leadership Potential
As I continued working with clients, I found myself not just coding but also interacting with business leaders and stakeholders. This exposure made me realize how critical it was to understand the bigger picture—not just the technical side but also the business needs, challenges, and strategies. I saw how I could contribute more by helping teams collaborate more effectively, guiding them through technical challenges, and aligning their work with business goals. It was at that point that I recognized that leadership was something I could do, and it wasn’t just about being the best coder in the room; it was about empowering others to achieve success.
Pursuing an MSc in IT, Major in Management and Leadership
To gain a deeper understanding of leadership, I decided to pursue an MSc in IT, specializing in management and leadership. During those three years of studying, I began to shift my focus from simply developing software to developing people. My academic journey opened my eyes to how much more I could contribute not only through my technical skills but also as a leader. I dedicated my thesis to ‘Management of Virtual Teams in Startup Environments,’ a topic that I found both challenging and rewarding. This research emphasized that, in today’s fast-paced tech environment, soft skills—such as communication, empathy, and conflict resolution—are the key ingredients for successful leadership, particularly in distributed teams.

The Challenges
Letting Go of Technical Work
One of the toughest challenges was letting go of the technical work that had been the core of my career. As a leader, I had to transition from being a hands-on engineer to overseeing the work of others, providing guidance and making high-level decisions that would steer the direction of the projects. This shift wasn’t always easy. I had to learn to trust my team and empower them to make decisions on their own, knowing that I couldn’t (and shouldn’t) be involved in every detail.
Managing People, Not Just Projects
Another challenge was navigating the dynamics of managing people. Being a leader meant that I had to juggle personalities, motivations, and expectations. Every team member had different needs, and understanding how to motivate, mentor, and guide them became just as important as the technical aspects of the job.

Overcoming Imposter Syndrome
Like many new leaders, I struggled with imposter syndrome. I questioned whether I was truly capable of leading teams effectively. But with time, I learned to focus on my strengths, trust in my experiences, and embrace my leadership role.
The Tech Leadership Mindset
Empowering Others to Lead
As I evolved into a leadership role, I realized that being a great leader isn’t about having all the answers. It’s about empowering others to come up with their solutions. My job became more about mentoring my team and providing them with the resources and confidence they needed to thrive.
Big Picture Thinking
I began seeing the bigger picture—how the technical work we were doing fit into the broader goals of the business. My focus shifted from just the immediate technical tasks to aligning the team’s work with the company’s strategic goals. This shift has been one of the most rewarding aspects of my leadership journey.

Key Lessons Learned in Leadership
Effective Communication
One of the most important lessons I’ve learned as a leader is the power of communication. Being transparent, setting clear expectations, and providing regular feedback have become central to my leadership style. I’ve learned to listen more, not just to solve problems but to understand what my team members are going through.
Empathy and Emotional Intelligence
Empathy has become one of the cornerstones of my leadership. Understanding my team’s emotions, frustrations, and aspirations has helped me connect with them on a deeper level. This emotional intelligence has allowed me to build trust, improve collaboration, and ultimately drive better results.
Decision-Making
Leadership has taught me that decision-making is an ongoing process. It’s not always about making the right choice immediately but about learning from each decision and course-correcting along the way. I’ve learned to trust my instincts, but I’ve also come to value feedback from my team to inform my decisions.
Looking Back and Forward
Reflecting on the Journey
Looking back on my journey from engineer to leader, I am grateful for the growth and experiences that have shaped me. From my early days as a freelance web developer to leading teams through complex technical challenges, each step has been a learning experience that has contributed to the leader I am today.
Looking Forward
I’m excited for the future of leadership in tech, as the industry continues to evolve. I know there’s always more to learn, and I am committed to growing as a leader—continuing to empower my teams, embrace new challenges, and help drive the future of technology.
-
Balancing Tech Debt and New Features: Practical Approach
As the tech lead responsible for keeping our product both evolving and maintainable, I’ve spent countless hours wrestling with the age-old tension between shipping new features and paying down technical debt. Over the years, I’ve distilled our approach into practical principles and tactics that let us move fast and stay sane.
The Dilemma
Every time we rush out a feature, we carry a little “interest” on our codebase—uncovered edge cases, outdated libraries, or quick-and-dirty workarounds. Left unchecked, this interest compounds:
- More bugs crop up in legacy areas as the codebase grows
- Slower performance and longer builds frustrate both users and engineers
- Onboarding new teammates becomes a slog when the code feels like spaghetti
Yet customers demand innovation, and market windows don’t wait for perfect code. How do we keep one foot on the gas and avoid crashing into a wall of technical debt?
Guiding Principles
- Maintainability ≈ Velocity
Treat clean, well-factored code as a feature in its own right. Every layer of indirection, every clear API boundary, buys us speed later on. - Bounded Contexts
Break the system into domains (Auth, Card Sharing, Lead Processing, etc.) with their data stores. That way, debt in one area doesn’t spill over into another. - Strangler Fig Pattern
Incrementally replace monolith endpoints behind an API gateway—route a slice of real traffic to new services, watch for issues, and expand until the old code can be retired. - Infrastructure as Code
Declare your deployments (Helm on GKE, Pub/Sub topics, service mesh policies) so you can replicate environments, roll back safely, and automate testing pipelines.
Our Tactical Playbook
1. Carve Out “Debt Budget” in Every Sprint
We reserve 10–20% of our sprint capacity for small-to-medium refactors and bug fixes—what some teams call a “debt quota”. That keeps the debt from sneaking up on us.
2. Clean As You Go
Inspired by restaurant kitchens, we treat each pull request as a chance to tackle a sliver of debt:
- Rename confusing variables
- Simplify nested conditionals
- Update one outdated dependency
This habit prevents “debt dumps” that stall feature work.
3. Triage Big Debt Items Separately
When a refactor spans multiple days or teams, we schedule a dedicated “cleanup sprint” every 4–5 sprints. This focused time lets us remove foundational obstacles before they grow moss.
4. Make the Payoff Crystal-Clear
Every technical debt story in our backlog spells out a measurable outcome for non-technical stakeholders:
“Refactoring our checkout module context will reduce checkout time by 30%, boosting conversion and reducing error rates.”
5. Track & Visualize Debt Metrics
We monitor:
- Debt Ratio: Estimated cost to fix vs. cost to build new features
- Code Churn: % of lines rewritten over time
- Remediation Cost: Sprint-equivalent to clear prioritized debt
Involving the Whole Team
Technical debt isn’t just an engineering problem; it’s a product concern. We regularly:
- Educate stakeholders on how debt impedes future innovation
- Run “Techrospectives” in retrospective meetings to balance feature vs. debt work
- Adjust our roadmap dynamically based on debt thresholds and business priorities
This transparency turns debt reduction into a shared goal rather than a hidden chore.
Continuous Improvement
Balancing debt and features isn’t a one-and-done exercise—it’s an ongoing rhythm. We refine our debt budget, revisit our metrics, and adapt our processes every quarter. The secret sauce is consistency: small refactors today prevent massive rewrites tomorrow.
Conclusion
In my experience, the healthiest development teams don’t choose either velocity or maintainability—they build velocity through maintainability. By embedding debt reduction into our process, measuring its impact, and keeping everyone in the loop, we deliver new features at pace and keep our codebase clean enough to sustain innovation for the long haul.
-
Migrating Our Monolith to Microservices on GCP
As the tech lead on this project, I oversaw the transformation of our legacy monolithic application—handling everything from user accounts and digital card sharing to lead capture and CRM integration—into a suite of independent microservices running on Google Cloud Platform. In this article, I’ll share both the theoretical underpinnings and the hands-on steps we took to achieve a scalable, resilient, and fast-release architecture.
1. Why We Needed to Change
When we hit our stride at large industry events, our single-instance deployment struggled:
- Traffic Spikes: QR scans and lead submissions would jump 5×, causing timeouts and memory pressure.
- Slow Releases: Even minor updates took 30–45 minutes to deploy, locking our teams out of rapid iteration.
- Cascading Failures: A bug in our CRM sync logic would sometimes stall login requests, degrading the entire user experience.
We needed a way to scale features independently, reduce blast radius of failures, and accelerate our delivery pipeline.
2. Core Principles That Guided Us
Before writing a single line of new code, we aligned on key microservices concepts:
- Bounded Contexts: We drew clear boundaries—Auth, Card Sharing, Lead Processing, CRM Sync, and Analytics—so each team owned its domain and data.
- Strangler Fig: We planned to incrementally replace monolith endpoints, routing a fraction of real traffic to new services, then steadily increasing until the old code could be retired.
- Single Responsibility: Every service would do one thing well, reducing complexity and making testing and deployment straightforward.
- Decentralized Data: Moving from one PostgreSQL instance with 30 tables to multiple Cloud SQL instances kept schemas focused and migrations safer.
- Infrastructure as Code: We defined our GKE deployments, Helm charts, and API Gateway configs declaratively to maintain consistency across environments.
3. Our Starting Point: The Monolith
I often remind the team how our stack looked in production before migration:
Layer Tech Role Front-end React 18 + Redux Next.js SSR for landing pages API & Logic Node.js 16 + Express.js ~20 000 LOC, JWT auth Database PostgreSQL (Cloud SQL) Shared schema, complex migrations Job Queue Redis + Bull Background jobs for emails & retries This tight coupling meant one change could ripple everywhere.
4. Mapping Out Bounded Contexts
We held a workshop to carve out our domains:
Service Owned Data Responsibilities Auth users, roles Signup, login, JWT generation Card cards, shares QR/NFC generation, share logging Lead leads, events Consuming share events, data enrichment CRM Sync sync_jobs Dispatching and retrying webhooks Analytics metrics Aggregating usage data, dashboards Each service would communicate via Pub/Sub topics—
CardShared,LeadCaptured, etc.—enabling asynchronous, reliable workflows.5. Our Migration Approach
Here’s how we systematically strangled the monolith:
- Set Up GCP API Gateway
- Configured a single edge entry point; enforced JWT validation before traffic hit our services.
- Extract Auth Service
- Spun up an Express.js/TypeScript repo.
- Migrated
/signup,/login,/profileendpoints. - Deployed on GKE under
/auth/*and toggled monolith redirects.
- Extract Card Service
- Ported QR/NFC logic into its own Node.js service.
- Published
CardSharedevents to Pub/Sub. - Ran 10% of share traffic through the new service, then ramped up.
- Build Lead Service
- Subscribed to
CardShared, enriched lead data, wrote to its own Cloud SQL. - Ensured idempotency using unique event IDs.
- Subscribed to
- Launch CRM Sync Service
- Created a microservice for webhook dispatch with Redis + Bull for retry and dead-letter queues.
- Repointed all CRM calls from the monolith to this service.
- (Optional) Analytics Service
- Later, we isolated reporting to a Python service reading from its own analytics database.
By the end, the monolith served only fallback traffic until we fully decommissioned each module.
6. Infrastructure and Deployment
Our stack on GCP looked like this:
- API Gateway handling routing, JWT auth, and rate limits at the edge.
- Istio Service Mesh enforcing mTLS, circuit breaking, and capturing telemetry to Cloud Monitoring.
- Cloud Build pipelines with automated testing, image builds, and Helm deployments.
- Observability via Prometheus, Grafana, and Jaeger to trace cross-service calls.
7. Testing Strategy
To ensure quality at each stage:
- Contract Tests: We used Pact to guarantee new services met monolith expectations before cutover.
- Integration Tests: Jest and supertest for HTTP endpoints; isolated Cloud SQL instances in Docker for CI.
- End-to-End Smoke Tests: Playwright against our staging cluster to validate critical flows.
- Load Testing: k6 scripts simulating thousands of share events per second to tune autoscaling.
Each build ran tests automatically, preventing regressions.
8. Lessons Learned
What Worked:
- Incremental migration minimized risk and allowed early wins.
- Pub/Sub decoupling made it easy to add new consumers (analytics, alerting).
- Service mesh policies improved security and reliability without code changes.
Challenges:
- Ensuring data consistency required careful versioning of our event schemas.
- Team coordination across multiple repos demanded robust CI/CD governance.
Conclusion
Migrating this platform was a journey of balancing theory with practical constraints. If you’re about to embark on a similar path, remember: start small, iterate quickly, and always keep your teams aligned on the end goal.
-
Designing a Modern Scalable E-Commerce System
Introduction
In this article, we walk through the design of a modern, scalable e-commerce system.
The goal: to create an architecture that is resilient, high-performing, extensible, and can handle the realities of a busy, dynamic online store.Our task is to design:
- Product Management (browse/search/add products)
- Inventory Control (manage stock levels)
- Order Processing (cart, checkout)
- Payment Processing (external credit card integration)
- Shipping Management (select address, prepare shipment)
We use Domain-Driven Design (DDD) principles, Event-Driven Architecture (EDA), and a microservices approach for decoupling.
Let’s dive into the journey!
System Design: Step-by-Step
1. Defining Bounded Contexts
We divide our system into bounded contexts for clear responsibility separation:
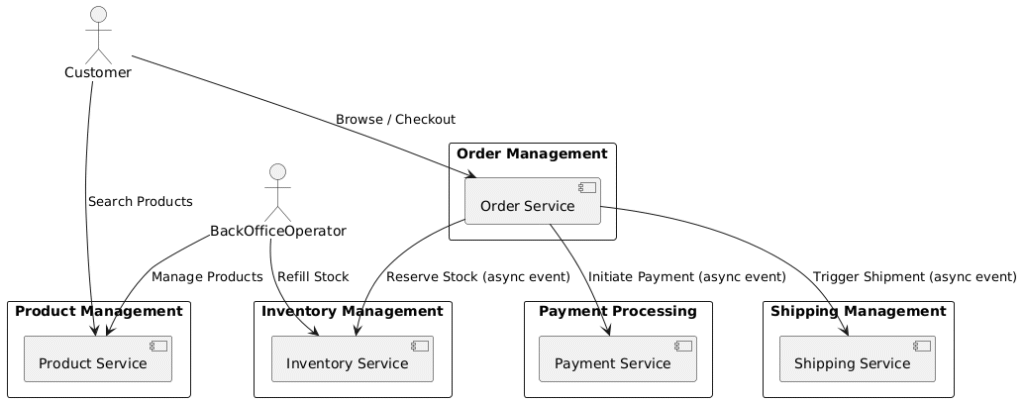
Each service owns its own database and communicates via asynchronous events using a message broker like Kafka.
2. Modeling Aggregates and Entities
Following DDD, we model our key entities:
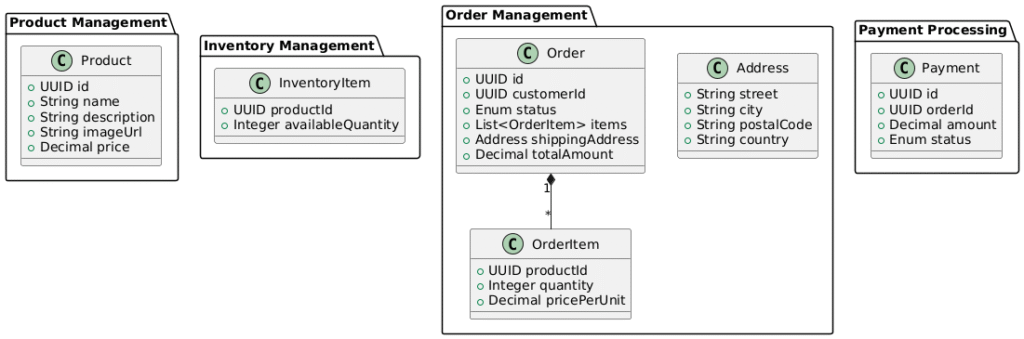
3. Event-Driven Checkout Flow
We implement a choreographed event-driven flow during checkout:

This flow allows services to scale independently while ensuring a resilient checkout process.
4. Commands, Events, and Event Payloads
Here are some sample event payloads:
OrderCheckoutStarted
{ "eventType": "OrderCheckoutStarted", "orderId": "order-123", "items": [ { "productId": "prod-456", "quantity": 2 } ], "customerId": "cust-789" }StockReserved
{ "eventType": "StockReserved", "orderId": "order-123", "success": true }PaymentSucceeded
{ "eventType": "PaymentSucceeded", "paymentId": "pay-001", "orderId": "order-123", "amountPaid": 199.99 }5. Database Schema Highlights
Each service manages its own tables:
Product Service –
productsTableColumn Type Description idUUID (PK) Product unique ID nameVARCHAR(255) Product name descriptionTEXT Product description image_urlVARCHAR(500) Image link priceDECIMAL(10,2) Product price created_atTIMESTAMP Created timestamp updated_atTIMESTAMP Updated timestamp CREATE TABLE products ( id UUID PRIMARY KEY, name VARCHAR(255) NOT NULL, description TEXT, image_url VARCHAR(500), price DECIMAL(10,2) NOT NULL, created_at TIMESTAMP DEFAULT now(), updated_at TIMESTAMP DEFAULT now() );Searchable by name & description. Recommend indexing
name,descriptionfor faster search.Inventory Service –
inventory_itemsTableColumn Type Description product_idUUID (PK, FK to products) Links inventory to product available_quantityINTEGER How much stock is available reserved_quantityINTEGER Items temporarily reserved last_refill_atTIMESTAMP Last refill time CREATE TABLE inventory_items ( product_id UUID PRIMARY KEY, available_quantity INTEGER NOT NULL, reserved_quantity INTEGER DEFAULT 0, last_refill_at TIMESTAMP DEFAULT now() );Handle stock updates atomically.
available_quantitymust decrease when reserved.Order Service –
ordersTableColumn Type Description idUUID (PK) Order ID customer_idUUID Customer reference statusENUM(‘CREATED’, ‘PAID’, ‘CANCELLED’) Current status total_amountDECIMAL(10,2) Order total price shipping_addressJSONB Embedded shipping address created_atTIMESTAMP When order created updated_atTIMESTAMP Last update time Order Service –
order_itemsTableColumn Type Description idUUID (PK) Order item ID order_idUUID (FK to orders) Related order product_idUUID (FK to products) Ordered product quantityINTEGER Number of items price_per_unitDECIMAL(10,2) Price at the time of order Payment Service –
paymentsTableColumn Type Description idUUID (PK) Payment ID order_idUUID (FK to orders) Related order amountDECIMAL(10,2) Payment amount statusENUM(‘PENDING’, ‘SUCCEEDED’, ‘FAILED’) Payment state created_atTIMESTAMP Created timestamp Shipping Service –
shipmentsTableColumn Type Description idUUID (PK) Shipment ID order_idUUID (FK to orders) Related order addressJSONB Shipping address shipment_statusENUM(‘PENDING’, ‘SHIPPED’, ‘DELIVERED’, ‘FAILED’) Tracking status created_atTIMESTAMP Created timestamp And so on for payments and shipments.
Use UUIDs everywhere for easy service boundaries (no clashing PKs).
Add indexes on
product_id,order_id,customer_idfor fast joins.Partition orders table if traffic is huge (e.g., by creation year).
Use JSONB for flexible address storage (avoids needing a separate Address table).
6. Event-Driven Architecture:
Choreography vs Orchestration
Quick Definitions
Term Meaning Choreography Each service reacts to events and performs its action independently. No single service coordinates everything. Orchestration A central service (Orchestrator) controls the flow, asking each service what to do next, waiting for replies.
Example with our E-Commerce Checkout
If Choreography:
Order ServiceemitsOrderCheckoutStarted.Inventory Servicelistens → reserves stock → emitsStockReserved.Payment Servicelistens → initiates payment → emitsPaymentSucceeded.Shipping Servicelistens → ships the order.- NO master controller.
Each service only listens and reacts.
✅ Pros:
- Low coupling between services.
- System is very scalable.
- Easy to add new behaviors (new services can listen to events).
❌ Cons:
- Harder to debug.
- No central place that knows the whole flow.
- Failure recovery (e.g., retry stock reservation) is complex.
If Orchestration:
Order Servicebecomes the orchestrator.- It:
- Calls
InventoryService.ReserveStock() - If success, calls
PaymentService.InitiatePayment() - If success, calls
ShippingService.InitiateShipment()
- Calls
- Synchronous or callback-based communication.
✅ Pros:
- Easy to debug (Order Service sees everything).
- Central control over flow and retries.
- Explicit logic for recovery paths.
❌ Cons:
- Tighter coupling between services.
- Scalability bottleneck if OrderService is overloaded.
- Harder to evolve new flows dynamically.
7. Why Choreography (Not Orchestration)?
In our case, choreography was better because:
- Low coupling = easier to evolve services
- High scalability (no single orchestrator bottleneck)
- Simpler for distributed transactions
Recovery is handled using:
- Dead letter queues (DLQ)
- Retry mechanisms
- Idempotent processing
8. Realistic Timeline: Checkout to Shipment
Step Service Action Latency 1 Order Service Validate + emit event ~50ms 2 Inventory Service Reserve stock ~100ms 3 Payment Service Process payment ~500ms 4 Shipping Service Start shipping ~100ms Total time to confirm checkout: ~850ms to 1.2 seconds.
Smooth, real-time user experience.Conclusion
Through careful domain modeling, event-driven design, and clean service separation,
we created an e-commerce architecture that is:- Highly scalable
- Resilient to failures
- Extendable for new features
- Aligned with real-world latency expectations
This approach isn’t just theoretical — it’s the foundation for modern platforms like Amazon, Shopify, and Walmart’s e-commerce engines.
Event-Driven + Domain-Driven = Futureproof Architecture.
-
A Layered Testing Strategy for SME Loan Platform
While this Loan App system dates back to 2018—built on Laravel 5.x and a React 16 (without Hooks) front-end, it had a structured, layered test suite. In 2018, the popular choices included ESLint and JSCS for linting, PHPUnit for PHP, Jest + Enzyme for React, and Cypress or Selenium for end-to-end. Below, we’ll map out five layers of testing with tools available at the time.
- Static Analysis (ESLint, JSCS, PHP_CodeSniffer, PHPMD)
- Unit Tests (PHPUnit, Jest + Enzyme)
- Integration Tests (Laravel HTTP Tests, nock or fetch-mock)
- Component Tests (Jest + Enzyme, React Test Utilities)
- End-to-End Tests (Cypress or Selenium WebDriver)
1. Static Analysis: Linting & Style Checking
Tools: ESLint (with ES6/React plugins), JSCS, Prettier (early adoption), PHP_CodeSniffer, PHPMD
Why?
- Enforce consistent style and catch syntax errors before runtime
- Identify code smells in PHP (unused vars, complexity) via PHPMD
- Automate formatting with Prettier or JSCS
Front‑end Example (
.eslintrc.js):module.exports = { parser: 'babel-eslint', // support ES6+ syntax extends: ['eslint:recommended', 'plugin:react/recommended'], plugins: ['react'], env: { browser: true, jest: true, es6: true }, rules: { 'react/prop-types': 'warn', 'no-console': 'off' }, };Back‑end Example (
.phpcs.xml):<ruleset name="LoanApp"> <rule ref="PSR2"/> <rule ref="PHP_CodeSniffer\Standards\Generic\Sniffs\Namespaces\NamespaceDeclarationSniff"/> </ruleset>Run these tools locally and integrate into CI to block bad commits.
2. Unit Tests: Isolate Core Logic
Tools: PHPUnit 6.x (Laravel built‑in), Jest 22.x, Enzyme 3.x
PHPUnit Example (InterestCalculator):
// app/Services/InterestCalculator.php public function calculate($principal, $rate, $days) { return round($principal * $rate/365 * $days, 2); } // tests/Unit/InterestCalculatorTest.php class InterestCalculatorTest extends TestCase { public function testDailyInterest(): void { $calc = new \App\Services\InterestCalculator(); $this->assertEquals(8.22, $calc->calculate(10000, 0.30, 10)); } }Jest + Enzyme Example (DocumentTypeUtil):
// src/utils/documentType.js export function isValidPdf(file) { return file.type === 'application/pdf'; } // __tests__/documentType.test.js import { isValidPdf } from '../src/utils/documentType'; test('accepts PDF files', () => { const file = { type: 'application/pdf' }; expect(isValidPdf(file)).toBe(true); }); test('rejects non‑PDF files', () => { const file = { type: 'image/png' }; expect(isValidPdf(file)).toBe(false); });3. Integration Tests: API & Data Layer
Tools: Laravel HTTP Tests (built‑in), nock (for Node), fetch‑mock or jest‑fetch‑mock
Laravel Example (
LoanRequestController):// tests/Feature/LoanRequestTest.php public function testCreateLoanRequest(): void { $user = factory(User::class)->create(); $this->actingAs($user) ->postJson('/api/loans', [ 'institution_id' => 1, 'net_worth' => 50000, 'collaterals' => ['Real Estate'], ]) ->assertStatus(201) ->assertJson(['status' => 'pending']); $this->assertDatabaseHas('loan_requests', ['user_id' => $user->id]); }React Integration (fetch-mock):
// __tests__/upload.integration.js import fetchMock from 'fetch-mock'; import { uploadDocument } from '../src/api'; describe('uploadDocument', () => { afterEach(() => fetchMock.restore()); it('returns URL on success', async () => { fetchMock.post('/api/uploads', { url: '/docs/1.pdf' }); const response = await uploadDocument(new Blob()); expect(response.url).toBe('/docs/1.pdf'); }); });4. Component Tests: React UI Assertions
Tools: Jest + Enzyme (shallow, mount)
Example (LoanStatusCard):
import React from 'react'; import { shallow } from 'enzyme'; import LoanStatusCard from '../src/components/LoanStatusCard'; describe('<LoanStatusCard />', () => { it('shows pending status', () => { const wrapper = shallow(<LoanStatusCard status="pending"/>); expect(wrapper.text()).toContain('pending'); }); });Mock contexts or Redux stores as needed to supply props and state.
5. End‑to‑End Tests: Full User Journeys
Tools: Cypress 3.x (released mid‑2018), Selenium WebDriver with Mocha or PHPUnit
Cypress Example:
// cypress/integration/loan.spec.js describe('Loan Application Flow', () => { it('SME can submit a loan request', () => { cy.visit('/login'); cy.get('#username').type('owner1'); cy.get('#password').type('password'); cy.contains('Sign In').click(); cy.contains('New Loan Request').click(); cy.get('#institution').select('Bank A'); cy.get('#netWorth').type('75000'); cy.get('#collateral').attachFile('asset.png'); cy.contains('Submit').click(); cy.contains('Status: pending').should('be.visible'); }); });Run E2E tests on CI or locally—Cypress offers a fast, reliable runner in your browser.
Conclusion
A layered approach, linting, unit, integration, component, and E2E, ensures that each part of Laravel + React application remained reliable as we continued to enhance and maintain it.